The Categorical Data Type#
In our previous readings, we introduced the idea that not only can DataFrames and Series hold any of the numeric data types we’ve come to know and love from numpy — like float64 or int64 — but that they can also hold arbitrary Python objects in an object-type Series. Despite this flexibility, however, we also explained why object Series come with a significant performance penalty.
In this reading, we will discuss the category dtype (analogous to factors in the R programming language, if that means anything to you), a data structure designed specifically to address the limitations of object Series in certain circumstances.
The object Performance Penalty Review#
As a reminder, in our previous reading on the object dtype, we explored how object Series are actually implemented behind the scenes, and why their flexibility comes at the cost of performance. In short, numeric Series are fast and memory efficient because:
All the entries are of the same type, meaning Python can anticipate what it needs to do to each entry before it gets there (e.g., for integers
*will always mean integer multiplication), andBecause all the entries in the Series are the same size, they can be easily laid out in a regular fashion in the same location of your computer’s memory, making it easier for Python to retrieve Series entries.
Objects, by contrast, violate both of these results. Because one entry of an object Series could be an integer and another could be a string, the operation my_series * 2 could mean “multiply by 2” for one entry (the integer) and “create a new string that repeats this string twice” for another (the string). Moreover, because Python objects can vary dramatically in size and structure (a Python integer looks very different from a Python dictionary from your computer’s perspective), it’s very difficult for Python to store the contents of an object Series in a regular, predictable pattern in memory.
Enter The category dtype#
While there is no way to get all the benefits of object Series’ flexibility without some performance costs, over the years a few hacks have been developed to get good performance in certain use cases.
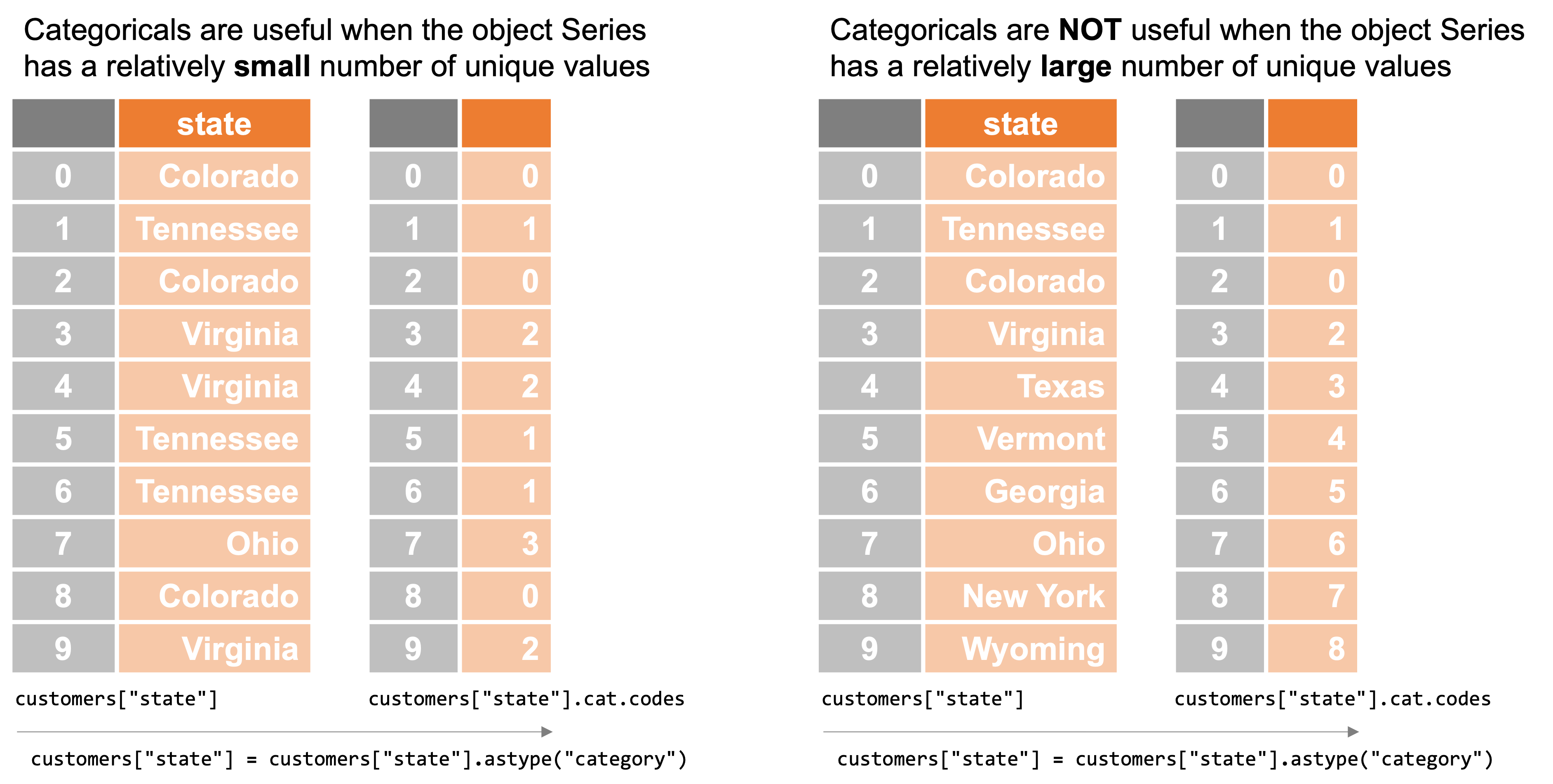
Categorical Series (Series with a category dtype) are designed to deal with a situation where a Series contains only text, and the actual values in that Series are repeated frequently. For example, suppose we have a DataFrame with information on hundreds of thousands of customers in the United States, and that one column of that DataFrame contains the name of each customer’s state of residence (substitute Province or any other sub-national administrative unit if states don’t resonate for you).
Because those state names are words, they are stored in an object Series by default. That, in turn, means that Python has created hundreds of thousands of Python objects — each containing the name of a customer’s state — and a vector containing addresses for each of those objects.
But as there are only 50 states in the United States, this might strike you as absurd, since most of those hundreds of thousands of Python objects are holding the same text! Surely we can do something more efficient than that?
Enter Categoricals. The idea of a category Series is to take a object Series that contains frequently repeated strings and:
Replace each unique string with a number (for example,
"Colorado"could become1and"Tennessee"could become2), andCreate a small “lookup table” that keeps track of what string is associated with each number.
Now pandas doesn’t need to create hundreds of thousands of Python strings to record each customer’s state, it can just make a numeric Series with state names replaced by the numbers 1-50, and a new small vector with the fifty names of states.
Moreover, in addition to saving memory, this also dramatically improves the performance of pandas. Suppose, for example, you want to subset for customers living in North Carolina. When these states were in an object Series, pandas would have to go to each entry, figure out where the associated Python object is stored, get that object, and check to see if it was the string "North Carolina".
But now, pandas can just go to the lookup table, see that "North Carolina" is the 33rd entry (and so is represented by the number 33 in our encoded Series of numbers), and look for values of 33 in that Series. Hooray!
But the best part is that, in most cases, the fact your data has been split into a numeric vector and a lookup table is actually entirely hidden from you, the user. For most operations, using a Categorical Series is just like using an object Series, just faster.
Categorical Series in Practice#
To illustrate how one works with Categorical Series, let’s make a toy version of this customer dataset:
import pandas as pd
import numpy as np
customers = pd.DataFrame(
{
"customer": ["Bob", "Aditya", "Francisco", "Shufan"],
"state": ["Colorado", "Tennessee", "Colorado", "Virginia"],
}
)
customers
| customer | state | |
|---|---|---|
| 0 | Bob | Colorado |
| 1 | Aditya | Tennessee |
| 2 | Francisco | Colorado |
| 3 | Shufan | Virginia |
customers.dtypes
customer object
state object
dtype: object
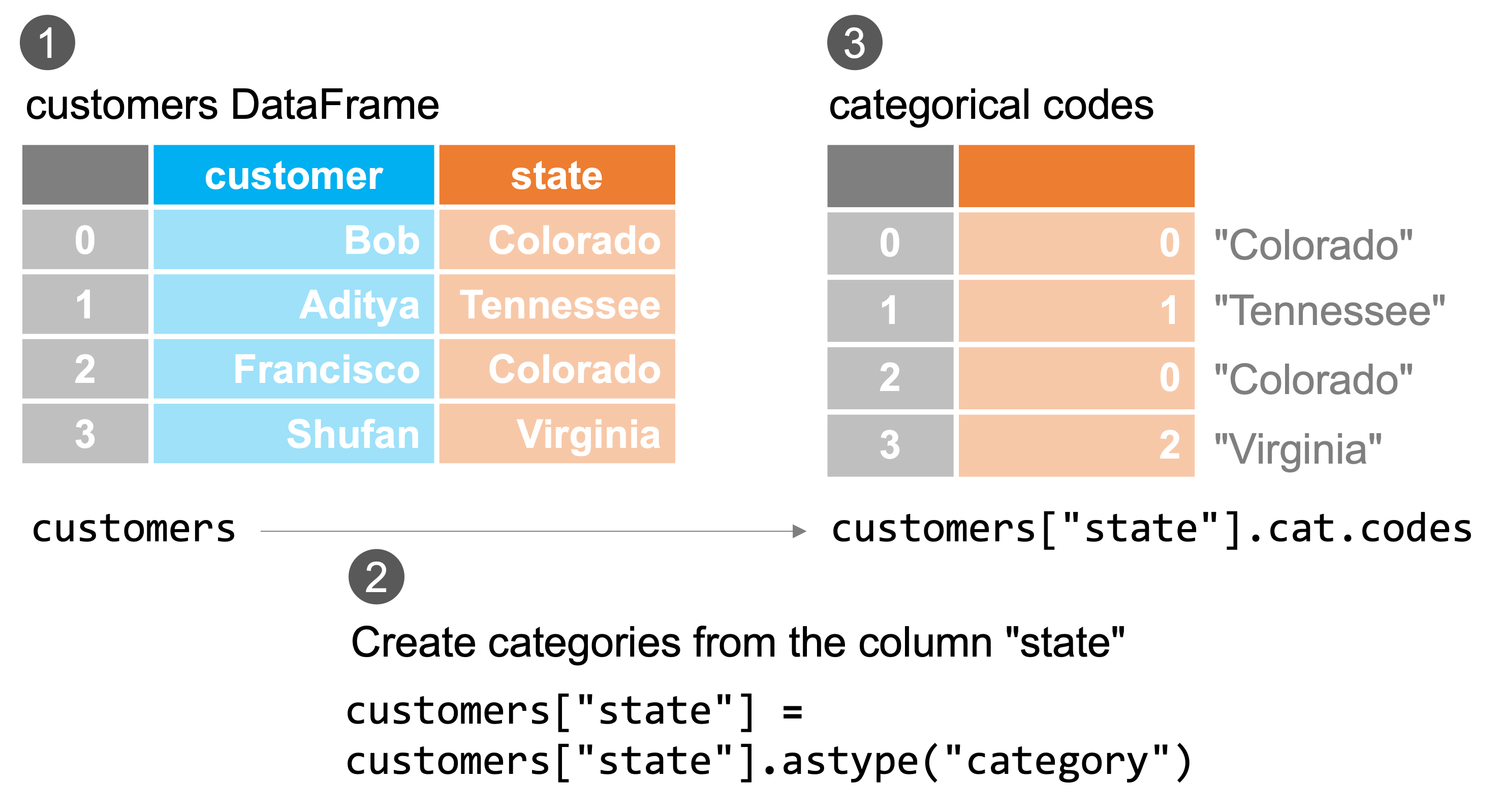
As we can see, state begins its life as a standard object Series, but we can convert it to a Categorical with .astype("category"):
customers["state"] = customers["state"].astype("category")
customers
| customer | state | |
|---|---|---|
| 0 | Bob | Colorado |
| 1 | Aditya | Tennessee |
| 2 | Francisco | Colorado |
| 3 | Shufan | Virginia |
As you can see, at first glance nothing about this column has changed. But if we pull it out, you can see it’s dtype is category and that the Categories associated with the Series (the lookup table) contains three values: "Colorado", "Tennessee" and “Virginia":
customers["state"]
0 Colorado
1 Tennessee
2 Colorado
3 Virginia
Name: state, dtype: category
Categories (3, object): ['Colorado', 'Tennessee', 'Virginia']
And if you want to, you can see the two underlying pieces directly:
customers["state"].cat.categories
Index(['Colorado', 'Tennessee', 'Virginia'], dtype='object')
customers["state"].cat.codes
0 0
1 1
2 0
3 2
dtype: int8
But as we said, in most cases category Series will operate just like object Series. Subsetting, for example, will work just as it would with an object Series:
customers.loc[customers["state"] == "Colorado"]
| customer | state | |
|---|---|---|
| 0 | Bob | Colorado |
| 2 | Francisco | Colorado |
The only place that problems may arise is that one cannot make arbitrary edits to a category Series — if you try and set a cell to have a value that isn’t in the current Categories table, you will get an error:
customers.loc[customers["state"] == "Colorado", "state"] = "Kansas"
TypeError Traceback (most recent call last)
/Users/nce8/github/practicaldatascience_book/notebooks/class_3/week_2/37_object_and_categorical_dtypes.ipynb Cell 22 line 1
----> 1 customers.loc[customers["state"] == "Colorado", "state"] = "Kansas"
[...]
TypeError: Cannot setitem on a Categorical with a new category (Kansas), set the categories first
You can add novel values, to be clear, you just have to add the category first:
customers["state"] = customers["state"].cat.add_categories(["Kansas"])
customers["state"]
0 Colorado
1 Tennessee
2 Colorado
3 Virginia
Name: state, dtype: category
Categories (4, object): ['Colorado', 'Tennessee', 'Virginia', 'Kansas']
customers.loc[customers["state"] == "Colorado", "state"] = "Kansas"
customers
| customer | state | |
|---|---|---|
| 0 | Bob | Kansas |
| 1 | Aditya | Tennessee |
| 2 | Francisco | Kansas |
| 3 | Shufan | Virginia |
Why Not Always Use Categoricals?#
Categoricals are great, but they are only useful when your object Series has a relatively small number of unique values. If you tried to convert an object Series with hundreds of thousands of addresses — and nearly all of them were unique — into a category Series, then pandas would have to create a lookup table that had… hundreds of thousands of unique entries (essentially, it would just be recreating your original object Series). And so there would be no real performance benefit.